22. System Design
Table of Contents
A. Introduction
The three stages to the interview:
- Problem: The interviewer gives you a purposely vague task.
- Clarification: You show leadership and experience by asking meaningful questions to clarify requirements and performance priorities.
- Presentation: You give an impromptu presentation on solutions (probably as you’re thinking of the solution.)
B. Methodology - Framework for System Design
-
Always start with clarification!
-
Ask about the priorities, scale and restrictions of the system
- How many users?
- How much data?
- How many requests per second?
- Latency requirements?
-
-
After understanding the requirements, start with a high level solution
- Start abstract and simple to lay out an end to end solution
- Draw an abstract diagram of the system
- the components should be technology agnostic and abstract away scaling and concrete methods
- eg: Checking whether the system prediction is real time, pre calculated batch or some hybrid
-
Start filling in some details; architectural components
-
eg: How models are delivered to the product? What type of infrastructure is required?
- Decribe the reasoning behind the design choices
-
add data models if necessary
-
-
Start with concerete component implementations
- Discuss the tradeoffs of the design choices
- eg: Why did you choose a particular database? Why did you choose a particular language?
-
Finishing touches
C. ML Model Development
-
Providing wide array of model types for the problem; it’s good to cover some breadth instead of naming one solution.
-
Offline training and evaluation
- Data used for training
- How to deal with data imbalances?
- Metrics used to compare models- Precision, Recall, F1 Score, ROC AUC, etc.
- Evaluation methods
- K-fold cross validation
- Training sample selection
- Data used for training
-
Online Evaluation
- Evaluate the model performance via A/B testing
- What metrics to use?
- Evaluate the model performance via A/B testing
-
Model lifecycle management
- Monitoring the model to ensure its health
- Operations to track to keep model performance
- How to manage the model lifecycle?
- How to deal with model drift?
- How to deal with model decay?
I. ML Operational Diffculties
A. ML Drifts
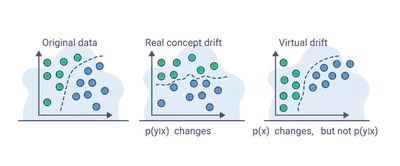
- Concept drift - The learned distribution changes over time due to behavioural changes
- Data drift - The learned distribution changes over time due to changes in the data
What to do about it?
- Setup data integrity and outlier monitoring
- Data errors slowly degrade
- Missing values
- Broken data pipelines due to bugs or API updates
- Setup model drift monitoring
D. Elements of Distributed Systems
Distributed system is an interconnected set of nodes that are linked by a network and share information between them.
I. Microservices
A design paradigm where an application is structured to collect several independent services. The characteristics of these services include:
- Independent deployment
- Highly scalable
- Loosely coupled
- Highly maintainable and testable
II. Service Discovery
A service discovery is a mechanism that allows services to find and communicate with each other without hardcoding the location of each other.
Eg: Apache zookeeper, consul, etcd
III. Load Balancing
A device that acts as a reverse proxy and distributes the network traffic across several different servers. There are two distinct types of load balancers:
- Layer 4
- Act upon data found in network and transport layer protocols (IP, TCP, FTP, UDP)
- Layer 7
- Distributes requests based on application data (HTTP, HTTPS, FTP, SMTP)
Standard algorithms for load balancing:
- Round Robin
- Least Connections
- Least Response Time
- Weighted Round Robin
IV. Databases
Refer to the databases page for more details.
V. Caches
A temporary storage with smaller capacity in memory with fast access time.
- Client Caching
- CDN Caching
- Web Server Caching
- Database Caching
- Application Caching
VI. File System Storage
A file is an unstructured collection of records. Two basic formats:
- Block storage - Organize data in blocks on disk
- Object storage
- Amazon S3
- Highlty scalable
VII. Message Queues
Lets services to communicate with each other asynchronously. It is a buffer between the producer and consumer.
- Producer - The service that produces the message and writes it to the queue
- Consumer - The service that consumes the message from the queue and reads it from the queue
Example: RabbitMQ, Kafka